保持在线安全,详解6种Web3社交工程攻击方式
Web3社交工程攻击是一种利用社交工程手段来操纵用户,泄露用户账号和密码等隐私信息,诱导用户授权,转移用户的加密货币和NFT资产。从而危及Web3网络的安全和隐私。以下,介绍六种社交工程攻击方式,并给出具体的预防建议。
1. Discord钓鱼
Discord作为加密用户的蓬勃发展中心脱颖而出,促进了社区内的连接和新闻分享。然而,它的受欢迎程度并不能使它免受潜在的威胁。在这个充满活力的空间中,恶意行为者可以偷偷地分发可疑链接,旨在夺取您宝贵的帐户凭证。
-
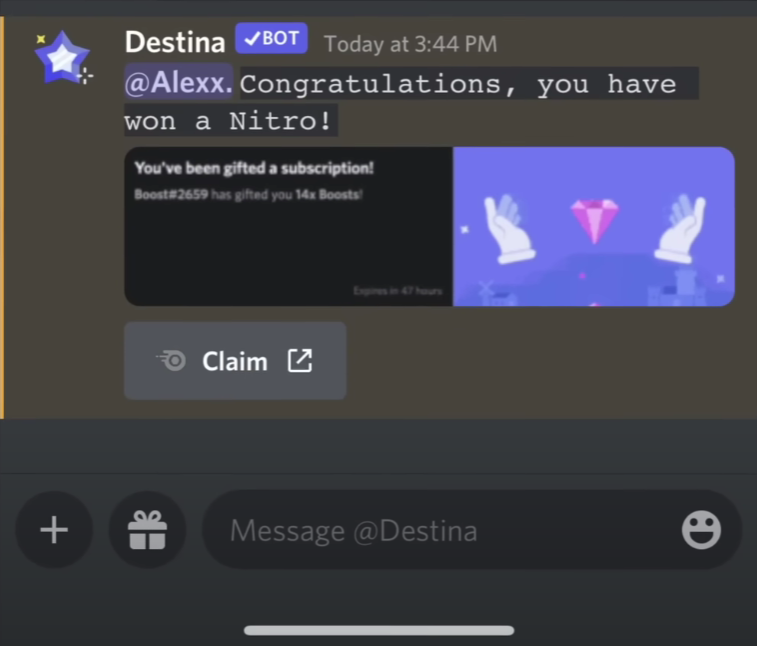
在 Discord 社区中,您可能会遇到类似的消息,声称您赢得了奖品,但它们实际上是伪装的网络钓鱼链接。
-
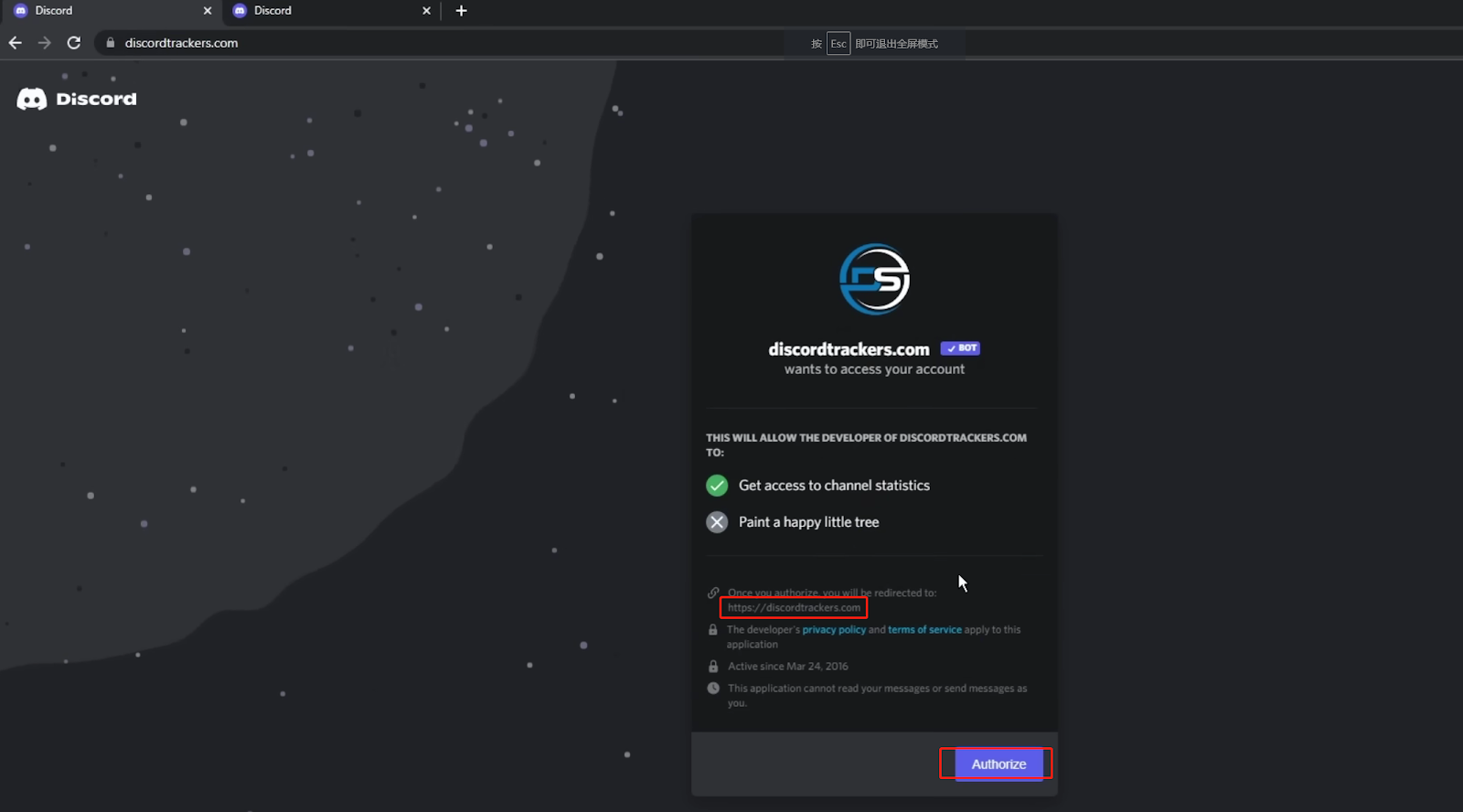
单击该链接会将您带到一个类似于 Discord 的网站,并提示授权。
-
点击授权后,会弹出另一个Discord登录窗口。
首先,我们无法将这个登录窗口拖到当前浏览器窗口之外;
其次,显示的地址中也有一些可疑的迹象。地址“https:\discord.comlogin”使用反斜杠()进行连接,而官方登录地址“ ”则使用正斜杠(/)进行导航。
-
该窗口页面看起来与合法的 Discord 登录窗口非常相似,差异很小。官方登录窗口图如下:
-
一旦用户在该钓鱼页面输入账户用户名和密码,其个人账户将立即被泄露,敏感信息将被暴露。随后,欺诈者可以利用这些信息未经授权访问用户帐户并从事欺诈活动。
在浏览器开发者模式下检查网页源码
你可以通过浏览器开发者模式,检查网页源码。
在上面的钓鱼过程中,点击授权后,弹出的假冒Discord登录窗口其实并不是一个新窗口,而是一个嵌入式界面。这是如何发现的呢?
在网页中按下F12键进入浏览器的开发者模式。在Elements选项卡中,您可以查看当前网页的HTML和CSS代码。针对页面中您觉得有问题的部分,比如,这个弹出的Discord登录窗口,您可以用鼠标点击该部分,通常可以在Elements面板中找到对应的代码部分。检查页面源码发现,这是一个标签,用于在网页中插入图像,src用来指定这个图像的路径。从官方的Discord登录窗口进入浏览器的开发者模式,如下图所示:
因此,当我们发现异常点之后,可以通过按F12进入浏览器的开发者模式,查看页面源码来判断我们的怀疑是否正确。尤其是在您点击陌生链接领取奖励时,更要持怀疑和谨慎的态度进行每一步操作。
2. Twitter钓鱼
在加密货币爱好者的热门平台Twitter上,出现了一个重大威胁——网络钓鱼。坏人巧妙地利用诱人的空投和免费的nft来操纵用户。通过将他们引导到欺骗性网站,这些攻击者精心策划了加密货币和宝贵的NFT资产的损失。
-
空投和免费 NFT 是许多人非常感兴趣的领域。诈骗者利用被劫持的经过验证的 Twitter 帐户发起活动并将用户重定向到网络钓鱼网站。
-
诈骗者利用合法 NFT 项目的资产来创建钓鱼网站。
-
他们利用 Linktree 等流行服务将用户重定向到模仿 NFT 市场(如 OpenSea 和 Magic Eden)的虚假页面。
-
攻击者将试图说服用户将其加密货币钱包(例如 MetaMask 或 Phantom)连接到网络钓鱼网站。毫无戒心的用户可能会在不知不觉中授予这些网络钓鱼网站访问其钱包的权限。通过这个过程,诈骗者可以转出以太坊 ($ETH) 或 Solana ($SOL) 等加密货币,以及这些钱包中持有的任何 NFT。
小心可疑的链接在Linktree
当用户在Linktree或其他类似服务中添加相关链接时,需要验证链接的域名。在点击任何链接之前,检查链接的域名是否与真实的NFT市场域名匹配。诈骗者可能会使用类似的域名来模仿真实的市场。例如,真实的市场可能是opensea.io,而虚假的市场可能是openseea.io或opensea.com.co等。
所以,用户最好选择手动添加链接,以下整理了手动添加链接的步骤:
-
首选,你需要找到想要链接的官网地址,并复制URL。
-
在Linktree中点击“Add link”,此时输入刚才复制的URL,点击“Add”按钮。
-
添加成功,即可在右侧看到“Opensea”。点击“Opensea”,即可重定向到官方的Opensea官方网站。
3. 网页篡改/假冒钓鱼
这里,介绍攻击如何构造自己的钓鱼网站域名,来假冒OpenAI官网,骗取用户连接自己的加密货币钱包,从而丢失加密货币或NFT。
-
诈骗者发送网络钓鱼电子邮件和链接,主题行例如“不要错过限时 OpenAI DEFI 代币空投”。该网络钓鱼电子邮件声称 GPT-4 现在仅供拥有 OpenAI 代币的人使用。
-
单击“开始”按钮后,您将被重定向到网络钓鱼网站,openai.com-token.info。
-
将您的钱包连接到网络钓鱼网站。
-
用户被引诱点击“点击此处领取”按钮,点击后,他们可以选择使用 MetaMask 或 WalletConnect 等流行的加密货币钱包进行连接。
-
连接后,钓鱼网站能够自动将用户钱包中的所有加密货币代币或 NFT 资产转移到攻击者的钱包中,从而窃取钱包中的所有资产。
识别真假域名
如果您知道如何识别URL中的域名,那么您将能够有效地避免网页篡改/假冒钓鱼。以下,解释域名的关键组成部分。
一般常见的网站要么是二级域名,要么是三级域名。
-
二级域名由主域名和顶级域名组成,比如,google.com。其中“google”是主域名,是域名的核心部分,表示网站的名称。“.com”是顶级域名,是域名的最后一部分,表示域的类别或类型,例如.com、.net、.org等。".com" 表示商业网站。
-
三级域名由主域名、子域名和顶级域名组成,比如,mail.google.com。"mail"是子域名,"google"是主域名,".com"是顶级域名。
解释上面的网络钓鱼网站,openai.com-token.info。
-
“openai”是子域名。
-
“com-token”是主域名。
-
“.info”是顶级域名。
很明显,这个钓鱼网站假冒的是OpenAI,OpenAI的官方域名是openai.com。
-
“openai”是主域名。
-
“.com”是顶级域名。
这个钓鱼网站是如何假冒的OpenAI呢?攻击者通过使用子域“openai”和主域“.com-token”,其中“com-token”使用连字符,使得这个钓鱼URL的前半部分看起来就像是“openai.com”。
4. Telegram 钓鱼
Telegram钓鱼是一个值得关注的网络安全问题。在这些攻击中,恶意分子的目标是控制用户的web浏览器,以获取关键帐户凭据。为了更清楚地说明这一点,让我们一步一步地看一个示例。
-
诈骗者在 Telegram 上向用户发送私人消息,其中包含最新《阿凡达 2》电影的链接,而且地址看起来简单明了。
-
打开链接后,您会到达一个看似真实的电影链接的页面,您甚至可以观看视频。然而,此时,黑客已经获得了对用户浏览器的控制权。
-
进入黑客的角度,让我们看看他们是如何利用浏览器漏洞利用工具来控制你的浏览器的。
-
在检查黑客的控制面板后,很明显他们可以访问有关浏览用户的所有信息。这包括用户的 IP 地址、cookie、代理时区等。
-
黑客有能力切换到 Google Mail 网络钓鱼界面,并对 Gmail 用户执行网络钓鱼攻击。
-
此时,前端界面变为Google Mail登录页面。用户输入他们的帐户凭据并单击登录按钮。
-
在后台,黑客成功接收到登录用户名和密码。利用该方法恶意获取用户账号和密码信息,最终导致用户信息泄露并造成经济损失。
检查网页源码中远程加载的JavaScript脚本
你可以进入浏览器开发者模式,检查网页源码中是否有远程加载的JavaScript脚本。这个脚本就是攻击者控制用户浏览器的关键。如何来确定你点击的链接中是否存在这种钓鱼脚本呢?
在上面的钓鱼过程中,你进入《阿凡达 2》电影的链接,可以按下F12键进入浏览器的开发者模式,发现该链接指向远程加载的 JavaScript 脚本。黑客通过执行脚本内容来远程控制浏览器,从而获取用户的账号和密码。
在普通网站上观看《阿凡达 2》电影,我们进入浏览器的开发者模式,并未发现任何指向远程加载的 JavaScript脚本。
5. Metamask钓鱼
这里,以Metamask插件为例,介绍攻击者如何利用此插件窃取用户钱包私钥的。
-
攻击者获取目标用户的联系信息,如电子邮件地址或社交媒体账号。攻击者伪装成信任的实体,如Metamask官方团队或合作伙伴,发送钓鱼电子邮件或社交媒体消息给目标用户。用户收到一封冒充 MetaMask 的电子邮件,要求验证其钱包:
-
用户点击“Verify your wallet”,进入以下页面,该页面声称是Metamask的官方网站或登录页面。在实际的钓鱼攻击过程中,我们发现了两种不同的钓鱼页面,第一个是直接要求用户输入密钥,第二个是要求用户输入recovery phrase。这两者的本质都是获取用户的metamask密钥。
-
攻击者获取受害者的私钥或recovery phrase,并可以使用这些信息访问和控制目标用户的Metamask钱包,通过转移或窃取目标用户的加密货币来获利。
检查Metamask邮件和域名
如果你需要在chrome上安装Metamask插件,官方链接是
一个存在钓鱼诈骗的链接是,请注意甄别 。
当你收到来自疑似Metamask的邮件时,需要注意甄别发件人和收件人的信息:
-
发件人的姓名和电子邮件地址存在严重的拼写错误:Metamaks而不是MetaMask。
-
收件人未写明你的真实姓名、一些其他可以表明你身份的信息以及需要做什么的更明确说明。这证明这封邮件可能是群发的,并非只发给你。
其次,你也可以通过域名来检查这些链接的真实性:
点击“Verify your wallet”进入钓鱼网页,metamask.authorize-web.org。分析此域名:
-
“metamask”是子域名
-
“authorize-web”是主域名
-
“.org”是顶级域名
如果你了解metamask官方的域名metamask.io,就很容易发现自己遭到了钓鱼攻击:
-
“metamask”是主域名
-
“.io”是顶级域名
这个钓鱼网站的域名metamask.authorize-web.org有 SSL 证书,这会欺骗用户认为这是一个安全的交易场所。但你需要注意,MetaMask的使用仅在注册顶级域名的子域名下。
6. VPN钓鱼
VPN是一种用于保护互联网用户身份和流量的加密技术。它通过在用户和互联网之间建立一个安全的隧道,将用户的数据加密传输,使第三方难以入侵和窃取数据。但是,很多VPN是钓鱼VPN,比如,PandaVPN、letsvpn和LightyearVPN等等。钓鱼VPN一般会泄露用户的IP地址。
当你使用VPN连接时,你的设备会将DNS请求发送到VPN服务器,以获取要访问的网站的IP地址。理想情况下,VPN应该处理这些DNS请求,并将其通过VPN通道发送到VPN服务器,从而隐藏你的真实IP地址。如果你使用的是钓鱼VPN,会发生DNS泄露,你的真实IP地址可能会被记录在DNS查询日志中,从而使你的在线活动和访问记录可被追踪到。这可能会破坏你的隐私和匿名性,特别是当你试图隐藏你的真实IP地址时。
IP泄露自检
当你使用VPN上网时,可以通过ipleak.net或ip8.com网站来测试VPN是否泄露了你的IP地址。这些网站仅能显示你的公共IP地址,即你的网络连接所分配的IP地址。如果你正在使用VPN服务,这些网站将会显示你所连接的VPN服务器的IP地址,而不是你真实的IP地址。这可以帮助你验证VPN是否成功隐藏了你的真实IP地址。
你可以通过下面的指示来检测你的IP地址是否被泄露:
-
打开浏览器并访问ipleak.net,这个网站会显示你当前的IP地址。如下图所示,你的IP地址显示为114.45.209.20。并指出”If you are using a proxy, it’s a transparent proxy.”。这表明你的IP地址没有泄露,你的VPN连接成功地隐藏了您的真实IP地址。
-
此时,你也可以通过ipconfig /all命令行查询你的真实IP地址,如果这里查询的IP地址和通过ipleak.net查询的IP地址不一致,则表明你的IP地址确实被隐藏了。如果一致,则表明你的IP地址暴露了。如下图所示,通过ipconfig /all查询本机真实IP地址为192.168.*.*,与上图所示的114.45.209.20不一致,IP地址未泄露。
总结
综上所述,我们详细介绍了六种Web3社交工程攻击方式,并提供了相应的识别和预防措施。为了有效避免Web3社交工程攻击,您需要提高对陌生链接、邮件以及来自社交平台的消息的警惕性。除此之外,我们还建议您了解如何在浏览器的开发者模式下检查网页源码,如何识别真假域名,如何自检IP地址是否泄露,并分析其中存在的安全隐患。